Chromium's architecture was designed to protect a user's OS from malicious websites. It is not designed to protect websites from each other.
For example, if attacker.com compromises the rendering engine, they can ask the browser kernel for bank.com's data and receive it.
The 2008 security architecture paper identifies origin isolation as a limitation: it was enforced by the rendering engine rather than the browser kernel.
How It Works
Chromium's security architecture consists of two parts:
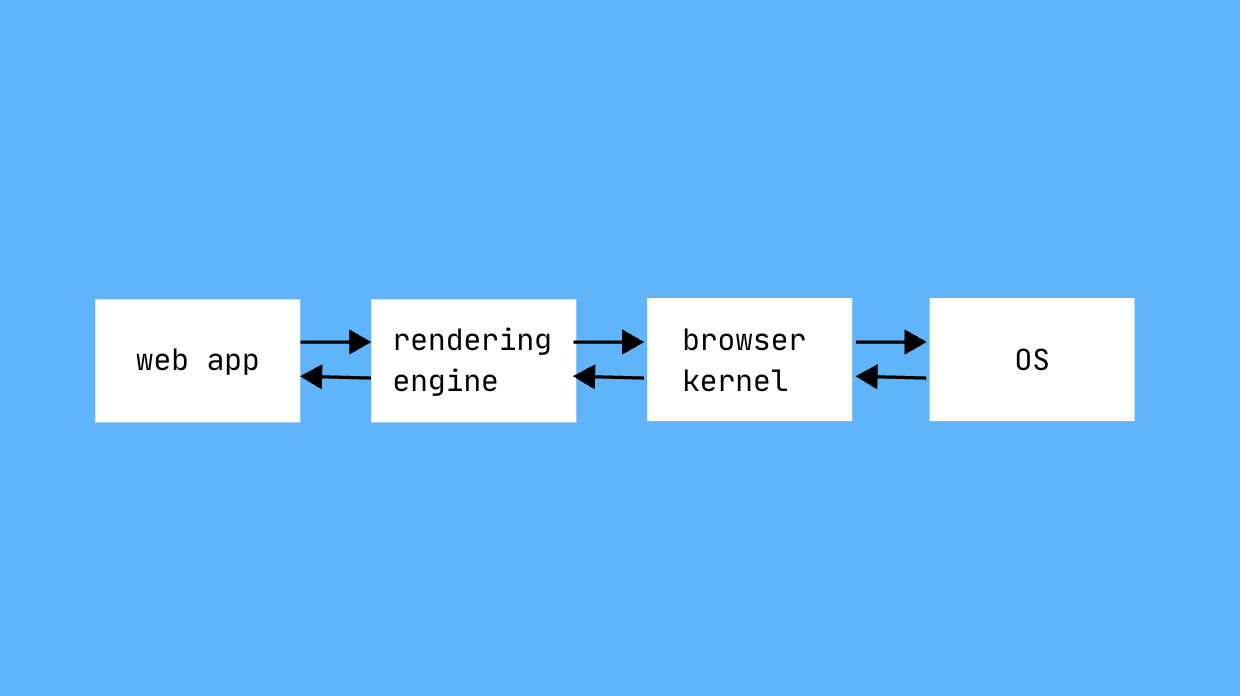
The security implication is that the web application has no direct interface with the filesystem. If a user wishes to download a file, the web application and rendering engine send a request to the browser kernel to enable the download, rather than doing it directly. The browser kernel displays and manages the UI for the user to download the file, and its interface is designed with transparency in mind.
The design goal is to make it clear what the user is downloading and that they consent to the interaction, rather than allowing a compromised rendering engine to download in the background without the user's awareness. This doesn't block potentially malicious downloads, but it enforces security through visibility.
The Catch
The 2008 security architecture paper created a browser that runs a single browser kernel. Historically, that kernel interacted with multiple rendering engines, each serving multiple origins. The browser kernel had access to data from all rendering engines. Each rendering engine should only have access to its own data, but the browser kernel did nothing to enforce this.
The browser kernel did not verify that calls from a rendering engine request only data from their origins, which means that if attacker.com compromised the rendering engine, it could ask the browser kernel for bank.com's data and receive it.
So, why didn't they have the browser kernel check origins?
One reason is that it isn't as simple as one tab = one origin: one rendering engine could load resources from multiple origins for images, fonts, payments, or advertisements. Forcing the browser kernel to differentiate among origins and determine which origins one rendering engine should be allowed to access would require memory and data overhead.
Furthermore, this architecture was built in response to the high-impact, prevalent threat to the web at the time: arbitrary code execution on a user's OS due to a web exploit.
Thread
It took years to develop a systematic method for mapping a rendering engine to a site, but Google eventually developed Site Isolation.
Spectre was a class of vulnerabilities that exploit speculative execution in CPUs that allowed a process to read memory outside its sandbox. That made process isolation an urgent matter, since if attacker.com and bank.com were running in the same process, the attacker could get bank data.
Google's answer was to give each site its own renderer process. This gives the browser kernel a simple and objective way to determine whether a request comes from a valid origin: just look at the process ID.
This was difficult because cross-origin iframes typically lived in the same rendering engine and process as their parent, and making these origins run in separate processes (developing out-of-process iframes or OOPIF) required rethinking fundamental web functions that assumed that these frames and their parents would share a process.
Once every origin lived in its own process, the browser kernel finally had the information it needed to do what the 2008 paper couldn't: enforce origin boundaries at the kernel level.