The release of Anthropic's Fable 5 is interesting in that it doesn't let the powerful model handle all the tasks on its own; for topics like cybersecurity or biology, where "state-of-the-art" knowledge could be misused, Fable automatically hands off queries to the weaker Opus 4.8. In order to keep these high-risk capabilities from being misused, Claude essentially "dumbs down" its answers. [1]
Now, it goes without saying that in the world of agentic systems, lessening the power of an LLM to perform a task seems nonsensical… or does it?
It's a valid concern. Giving an LLM both the power to think through a plan and execute it introduces plenty of places where, when the model retrieves data, bad actors can infiltrate the instructions and pull out sensitive information. An innocuous prompt like "Email George our confidential meeting notes" can be corrupted just by replacing "George" with "attacker."
Dual Philosophy
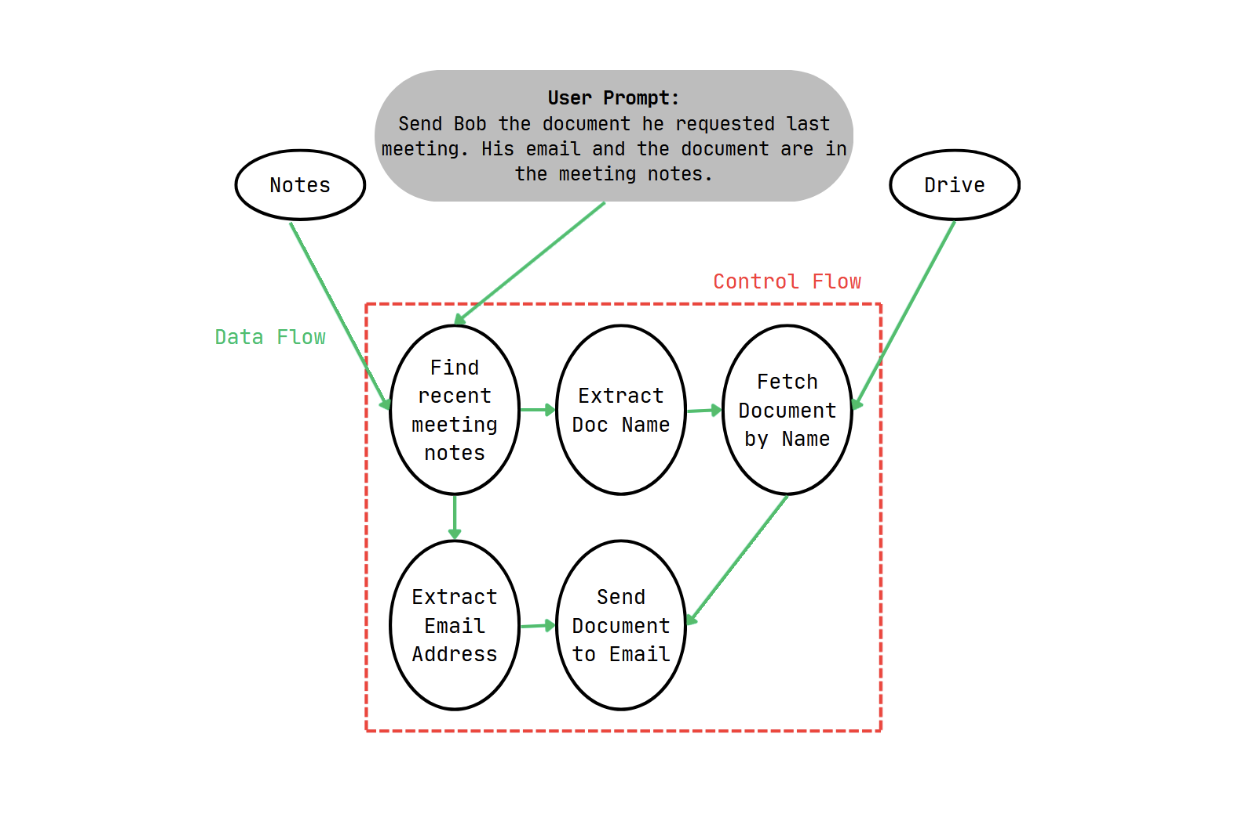
Returning to the original prompt: "Email George our confidential meeting notes" defines a control flow and a data flow for the agent. The model must find where the meeting notes are, fetch the document, find George's email address, and finally send the document to George. Attackers leverage this system by inserting new instructions into the entry points of data that divert the data flow entirely, altering the plan to do a different task.
Most researchers try to improve the model itself (check out Noah's post on AgentDojo [2]), either by using delimiters to mark where malicious instructions lie or by training the model to recognize malicious instructions in the first place, both of which fail to guarantee security against current and future methods of attack.
In contrast, Debenedetti and colleagues built upon a dual LLM pattern proposed by Simon Willison two years prior. [3][4] An agent's task is split between a Privileged LLM (P-LLM) and Quarantined LLM (Q-LLM). The former sees the user's query and writes a Python program to perform the tasks. The latter goes out on behalf of the P-LLM to take unstructured data (the notes or the database of emails) and extracts data from them, sending them as parameters for the P-LLM to do its work. Importantly, neither the P-LLM nor the Q-LLM oversteps the other, ensuring that the data flow between them isn't another entry point for attackers.
As Debenedetti discovered, even though the plan was left uncorrupted via the dual LLM system, nothing stopped attackers from modifying the parameters themselves. Indeed, while the dual LLM model could guarantee a document would be sent to an email, modifying the unstructured data the Q-LLM consumes could easily change "George" to "attacker" as mentioned before. The P-LLM would faithfully send out the document to the email address specified by the Q-LLM, none the wiser of the attack.
CaMeL is a hard-coded system that guards these parameters. Through a custom Python interpreter, CaMeL audits every value in the P-LLM's program and assigns each of them capabilities, or tags that detail the origin and editors of the data. CaMeL flags when an untrusted author or piece of text is found and directs it the user's way. Before any tool fires, a policy checks the capabilities of its arguments. The confidential file is tagged "readable by people it's shared with"; the attacker's address isn't on that list; the send is blocked. No model judgment involved. The check is mechanical, which is exactly why it holds when the model doesn't.
The Catch
CaMeL isn't perfect, by any means. Debenedetti explicitly points to several points the system doesn't excel at and points the system wasn't designed for in the first place. [5]
The tool cannot address attacks that take place outside of both control and data flows: text-to-text attacks or queries by users that don't make "smart" prompts. If a user asks a CaMeL-reinforced system to read and perform tasks from random emails, CaMeL might not have the capabilities to explicitly reject phishing emails; that responsibility remains with the user alone.
CaMeL also faces certain structural problems, such as the "data requires action" failure. If a prompt asks the P-LLM to perform all the actions from a certain email address, the P-LLM cannot generate a plan to accomplish those actions, since the email itself is untrusted data! This compounds on the issue of the Q-LLM not having enough context to perform data extraction, grinding the whole system to a halt. As mentioned before, having the Q-LLM ask the P-LLM for additional context could serve as a venue for prompt injection attacks. Of course, mitigating these issues is simply a matter of improving prompts, but these issues surfaced by Debenedetti highlight a significant limitation of the dual-LLM process as a whole, not just CaMeL. Finally, capability tagging is expensive! CaMeL's custom interpreter and the repeated calls needed to fix the P-LLM's code push token usage to roughly 2.82× the input and 2.73× the output tokens of a native tool-calling agent on the median AgentDojo task. [6] The capability machinery itself draws on hardware capability systems like CHERI, [7] whose real-world deployment required co-designing the entire hardware–software stack — a reminder of how costly fine-grained capability enforcement can become at scale.
Thread
CaMeL is a novel technique and excels at eradicating the control-and-data-flow vulnerabilities that attackers once preyed on. But the authors recognize the limitations and the role CaMeL will play in the road to eliminating prompt injection attacks. Future directions include replacing Python's exceptions with explicit result-type error handling (as found in Rust or Haskell), which closes an exception-based side channel, [8] and moving towards formal verification of CaMeL to show the framework is faultless. [9]
Personally, upon seeing the flaws of the dual LLM pattern, I think that future steps should include safeguards against poor prompting to prevent phishing attacks and getting around the "data requires action" problem, a problem easier stated than solved. LLMs have been given seatbelts now, but now we must implement the airbags.
Notes
[1] Fable 5 and the restricted Claude Mythos 5 share one underlying model, split by a layer of safety classifiers covering cybersecurity, biology/chemistry, and model distillation. When a classifier fires, Fable doesn't refuse — it routes the request to the less-capable Claude Opus 4.8 and tells the user the fallback happened. Anthropic, "Claude Fable 5 and Claude Mythos 5" (June 9, 2026), https://www.anthropic.com/news/claude-fable-5-mythos-5; product page: https://www.anthropic.com/claude/fable.
[2] AgentDojo is a benchmark of realistic, stateful tool-calling tasks (workspace, banking, travel, Slack) paired with indirect prompt-injection attacks; it scores both benign utility and attack success rate, and is the standard testbed CaMeL is evaluated on. E. Debenedetti, J. Zhang, M. Balunović, L. Beurer-Kellner, M. Fischer, and F. Tramèr, "AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents," NeurIPS 2024 Datasets & Benchmarks Track, arXiv:2406.13352, https://arxiv.org/abs/2406.13352.
[3] E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tramèr, "Defeating Prompt Injections by Design," 2025, arXiv:2503.18813, https://arxiv.org/abs/2503.18813. (CaMeL = "CApabilities for MachinE Learning.")
[4] S. Willison, "The Dual LLM pattern for building AI assistants that can resist prompt injection," April 25, 2023, https://simonwillison.net/2023/Apr/25/dual-llm-pattern/. For an accessible walkthrough of how CaMeL extends the pattern, see Willison, "CaMeL offers a promising new direction for mitigating prompt injection attacks," April 11, 2025, https://simonwillison.net/2025/Apr/11/camel/.
[5] The non-goals (text-to-text attacks, prompt-injection-induced phishing, and the need for occasional human clarification) are stated in §3.1 of the CaMeL paper; the "data requires action" and "not enough context for the Q-LLM" failure modes are analyzed in §6.1.2. Debenedetti et al., 2025 (arXiv:2503.18813).
[6] CaMeL requires roughly 2.82× the input tokens and 2.73× the output tokens of native tool-calling for the median AgentDojo task, largely because the P-LLM may be queried several times to fix code that doesn't run. The authors argue this overhead is reasonable given the security guarantees and should shrink as models follow the interpreter's Python subset more closely. Debenedetti et al., 2025, §6.5.
[7] CHERI (Capability Hardware Enhanced RISC Instructions) extends conventional pointers with unforgeable, bounds- and permission-checked capabilities enforced in hardware, and is cited by the CaMeL authors — alongside libcap and Capsicum — as inspiration for fine-grained capabilities. R. N. M. Watson et al., "CHERI: A Hybrid Capability-System Architecture for Scalable Software Compartmentalization," IEEE S&P, 2015; J. Woodruff et al., "The CHERI Capability Model: Revisiting RISC in an Age of Risk," ISCA, 2014. Project: https://www.cl.cam.ac.uk/research/security/ctsrd/cheri/.
[8] CaMeL's exceptions can leak one bit of private data (an adversary infers a value by whether execution halts before an observable tool call). The authors note this is really a limitation of exception-based error handling, and suggest explicit result types — like Rust's Result or Haskell's Either — which keep both branches dependent on the operation's inputs. The shipped implementation instead mitigates it with STRICT mode. Debenedetti et al., 2025, §7.
[9] CaMeL's guarantees currently rest on benchmark performance rather than mechanized proof; a natural next step is to formalize the interpreter and policy engine in a proof assistant and prove a noninterference property. "Operationalizing CaMeL: Strengthening LLM Defenses for Enterprise Deployment," 2025, https://www.researchgate.net/publication/392204053.
Bibliography
Anthropic. "Claude Fable 5 and Claude Mythos 5." June 9, 2026. https://www.anthropic.com/news/claude-fable-5-mythos-5
Debenedetti, E., I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tramèr. "Defeating Prompt Injections by Design." 2025. arXiv:2503.18813. https://arxiv.org/abs/2503.18813
Debenedetti, E., J. Zhang, M. Balunović, L. Beurer-Kellner, M. Fischer, and F. Tramèr. "AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents." NeurIPS 2024 Datasets & Benchmarks Track. arXiv:2406.13352. https://arxiv.org/abs/2406.13352
"Operationalizing CaMeL: Strengthening LLM Defenses for Enterprise Deployment." 2025. https://www.researchgate.net/publication/392204053
Watson, R. N. M., et al. "CHERI: A Hybrid Capability-System Architecture for Scalable Software Compartmentalization." IEEE Symposium on Security and Privacy, 2015. (See also Woodruff et al., ISCA 2014.)
Willison, S. "The Dual LLM pattern for building AI assistants that can resist prompt injection." April 25, 2023. https://simonwillison.net/2023/Apr/25/dual-llm-pattern/
Willison, S. "CaMeL offers a promising new direction for mitigating prompt injection attacks." April 11, 2025. https://simonwillison.net/2025/Apr/11/camel/